
О программировании на языке ACL. Заметки на разные темы.
Виктор Кон, . . . 7 мая 2022 года, . . . http://kohnvict.narod.ru
В середине апреля 22-го года я написал довольно большую статью, вот ссылка ![]() , с целью объяснить потенциальным пользователям языка ACL с чего и как начинать и какие есть возможности у моего языка программирования. Я дальше буду ее называть так -- статья ПШПВ. Первоначально была идея писать эту статью вечно и постепенно добавлять материал. Но потом я от этого отказался. Так у меня написано техническое описание языка. Там нет лишних слов и нет рисунков, но зато четко и подробно прописаны все особенности каждой операции каждой команды. Такие описания пишут по любому языку, и это обычно огромные тексты, которые структурируются и снабжаются навигаторами. Но которые все равно никто не читает. Впрочем так нельзя сказать. Лично я своим описанием пользуюсь постоянно, так как выучить все уже невозможно, а любая, даже малейшая неточность и . . . программа не будет работать. Но такой текст хорош для тех, кто все знает и делает супер-сложные программы. А новичкам это не поднять, да и охоты не будет.
, с целью объяснить потенциальным пользователям языка ACL с чего и как начинать и какие есть возможности у моего языка программирования. Я дальше буду ее называть так -- статья ПШПВ. Первоначально была идея писать эту статью вечно и постепенно добавлять материал. Но потом я от этого отказался. Так у меня написано техническое описание языка. Там нет лишних слов и нет рисунков, но зато четко и подробно прописаны все особенности каждой операции каждой команды. Такие описания пишут по любому языку, и это обычно огромные тексты, которые структурируются и снабжаются навигаторами. Но которые все равно никто не читает. Впрочем так нельзя сказать. Лично я своим описанием пользуюсь постоянно, так как выучить все уже невозможно, а любая, даже малейшая неточность и . . . программа не будет работать. Но такой текст хорош для тех, кто все знает и делает супер-сложные программы. А новичкам это не поднять, да и охоты не будет.
И я решил ту статью больше не дописывать и не переписывать. Написал я ее довольно быстро и как получилось, так и получилось. А вот новые тексты я решил писать в виде серии заметок или небольших рассказов на определенные темы. В основном тут будут какие-то новые вещи, которые я либо сделал только что, либо пересмотрел и переделал то, что было сделано раньше. А стиль будет такой же, как и в первой статье. То есть текст в произвольной форме, возможно с рассказами о посторонних предметах, а также примеры кода и рисунки. И текст будет нарастать постепенно. То есть это как бы журнал для чтения, который периодически выходит и что-то сообщает. Я постараюсь его как-то распространять, но что получится пока не ясно.
Содержание
01. Научная графика и суперкоманды.
02. Методы программирования. Новый способ работы с суперкомандами.
.
1. НАУЧНАЯ ГРАФИКА И СУПЕРКОМАНДЫ.
В статье ПШПВ про научную графику написано немного. На самом деле на такое программирование в моей жизни было потрачено довольно много времени. И об этом я здесь расскажу подробнее. В самом начале работы на компьютере ее просто не было. Графики все рисовали вручную по точкам на миллиметровой бумаге. Это такая бумага, на которую была нанесена сетка линий с шагом 1 мм. И было удобно ставить точки карандашом по известным координатам этой точки. Графиков было мало и их создание было отдельной сложной работой. Тогда и фотоаппараты были плохие. А еще раньше их тоже не было и люди рисовали картины. Так вот создание графиков было сродни рисованию картин.
Но уже в 70-х годах прошлого века результаты стали печатать на широкую бумагу по 120 символов на строку. И можно было строить графики прямо в печати. Ось аргумента обычно шла поперек строки, а ось функции -- вдоль строки. Бумага в то время расходовалась в огромных количествах, но зато можно было сразу видеть результат в графической форме. То есть экономить рабочее время. В то время даже картины рисовали в печати компьютеров, а также карты распределения двумерной функции, один аргумент вдоль строки, второй поперек, а разные значения функции показывали разными символами. Интернета тогда не было и каждый изобретал программы такого рисования самостоятельно. Я тоже написал много таких программ. Были у меня и программы, когда аргумент шел вдоль строки, а функция -- поперек. В этом случае число точек аргумента не превышало 100, но обычно этого хватало. А число строк я использовал таким сколько было на одном листе. Уже не помню сколько это было.
Персональный компьютер фирмы IBM с 16-битным процессором у нас появился в самом конце 80-х годов. Примерно в то же время я купил для сына домашний компьютер с 8-битным процессором и в виде клавиатуры, точнее под клавиатурой. Результаты работы он показывал на экране цветного ТВ. Это был первый в моей жизни цветной компьютер. На работе компьютер был монохромный, но он мог печатать на принтере и имел даже операционную систему ДОС. Домашний компьютер работал на языке Бейсик и был намного проще. Написать научные программы для таких компьютеров уже было не трудно. Собственно тогда все и было сделано. Уже в 1991 году я задумал создавать свой собственный язык программирования, а в 1992 году я уже вовсю на нем работал, хотя это была еще очень пробная версия.
Собственно, идея создавать свой собственный интерпретируемый язык программирования возникла как раз из необходимости программировать графику. В то время все работали на фортране и этот язык был идеальным для расчетов. С появлением персональных компьютеров в нем появилась и графика, но программировать ее было сложно. Графика быстро исполнялась, ведь в ней нет больших циклов и она не делает сложных расчетов. Но вот компиляция кода происходила медленно, компьютеры тогда были еще слабые. А сделать график сразу хорошо не получалось. Надо было смотреть на результат и исправлять неточности. И это было медленно. Это снова было похоже на рисование графиков вручную. Нужна была одна программа, которая читает текст и исполняет его. Время на интерпретацию текста было меньше, чем компиляция кода программы.
Первую программу-интерпретатор (далее ПИ) я написал на фортране. Параллельно я изучал постскрипт и написал на фортране другую программу, которая читала входные данные, организованные снова в некий примитивный язык программирования рисунков и создавала научную графику в виде текста на языке Постскрипт. То есть она просто один текст преобразовывала в другой текст. А постскрипт -- это тоже интерпретируемый язык и он исполнялся другими программами, которые массово использовались в системе Юникс, но были и в системе ДОС. Системы Виндовс тогда еще не было.
Начиная с 1995 года мне приходилось работать и в системе Юникс тоже. Это было во время командировок в город Гренобль во Франции. И там мне такая программа очень помогла. Фортран был во всех системах, в Юникс тоже. А вот на изучение графических программ в системе Юникс у меня не было времени. Там тогда, да и сейчас, все пользовались программой GnuPlot. А я на фортране автоматически создавал постскрипт код и рисовал графики, используя программы, которые его показывали. Были там и постскрипт принтеры. Одна моя программа, написанная в такой манере, до сих пор там используется. А научная статья, написанная об этом, до сих пор цитируется и по уровню цитирования среди моих статей она уже вошла в первую десятку.
Но у фортрана не только была неудобная графика. У него также были неудобные средства создания интерфейса программы с пользователем. Это было привязано к операционной системе и использовало готовые элементы этой системы. То есть программы, написанные в системе Виндовс, не работали в Юникс. И мне пришлось поменять язык программирования. В 2003 году я выбрал язык Java. И нисколько об этом не жалею. В то время его ругали за то, что он слишком медленный. Но все это прошло. Язык появился в 1995 году и поначалу реально был медленный. Но потом его интерпретатор был усовершенствован, а компьютеры стали намного быстрее. И уже даже в 2003 году все было вполне прилично. Язык Java создавал программы, которые во всех операционных системах работали одинаково и сразу. Но это все же не совсем интерпретируемый язык. Он компилируется.
Интересно, что Питон, единственный массовый интерпретируемый язык был создан примерно в то же самое время. Меня он тогда не заинтересовал, да я и немного знал о его существовании. Это сейчас его пропагандируют в каждом утюге и предлагают для изучения даже школьникам. Тогда все было не так просто. Этот язык я изучил совсем недавно, всего два года назад. И он мне не понравился. И синтаксисом, и организацией. Он слишком сложный, а часто и просто убогий. Особенно в области научной графики. Все программы были написаны давно и сильно устарели. Впрочем это был все тот же GnuPlot. Хотя на Питоне написано огромное количество программ, пользоваться ими не удобно.
Во всех интерпретируемых языках (Питон, Постскрипт, Javascript и другие) есть процедуры, как куски кода, которым присваивается имя и потом этот кусок можно использовать просто по имени. Это очень сокращает запись и позволяет легче ее читать. Разумеется есть процедуры и в моем языке ACL. Но я пошел дальше и стал записывать куски кода в файлы, которые находятся в специальной папке (proc). И такие куски я назвал суперкомандами. Они используются в коде программы как обычные команды, то есть просто по имени. Но перед именем команды стоит один символ #, а перед их именами стоят два символа ##. Однако польза суперкоманд резко возрастает, когда они написаны в универсальном виде и имеют набор входных данных.
Универсальный код с набором входных данных -- это уже полноценная программа для пользователей. Но пользователи не знают языка и им нужны окошки с подсказками, куда надо вводить числа. Это снова очень медленно и не позволяет работать автоматически. Для суперкоманд входные данные вводятся средствами языка ACL. Удобно, что этих средств не так много. Есть огромный массив реальных чисел r(), не такой большой массив целых чисел i(), текстовый массив t() и переменные, которые тоже сгруппированы в массивы. И такой набор доступен всем процедурам и любому коду, где бы он ни был записан.
Описание суперкоманд я начну с самой простой, которая называется ##sm (show memory). Она показывает на графике любую часть реального массива r(). Вот как это делается
#d 2 r(ZZ-10) J n ##sm
Чтобы не портить память входные параметры удобно записывать в конец большого массива r(), где стоят элементы, которые не часто используются в программах. Но разные версии ПИ имеют разный размер этого массива. ПИ дает информацию о том, какой у него размер в параметр s(109). Я предлагаю в начале каждой программы определять переменную ZZ=s(109) и в этой переменной как раз и находится размер массива. Туда пересылаются индекс первого элемента который, показывается на графике и их число. После этого n чисел можно смотреть на графике. Все остальное делается автоматически. Такая процедура весьма полезна для контроля работы программы в любом месте.
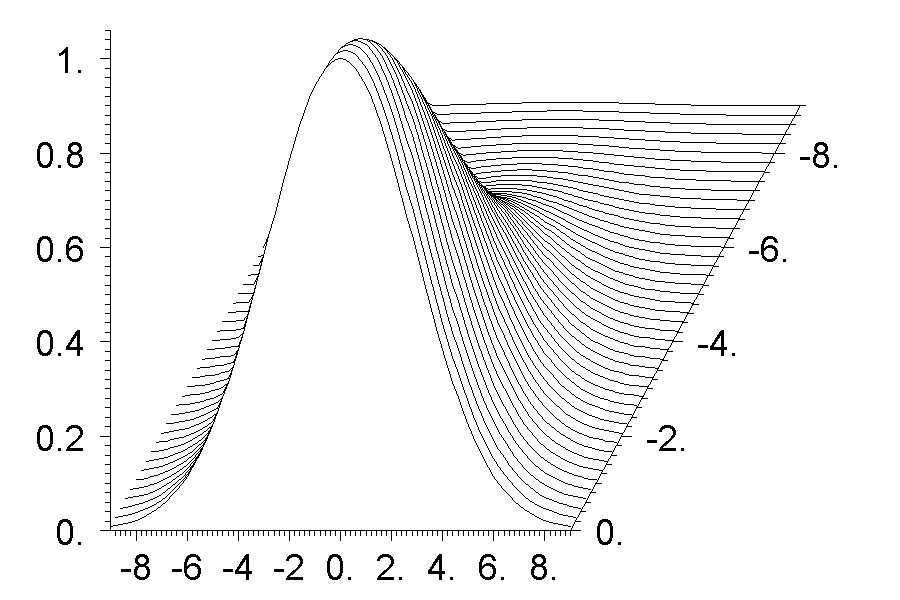
Она рисует плоский график одной функции, и на нем все определено. Но разумно иметь более универсальную программу. Такая программа называется суперкомандой ##smau (Show Меmory with Argument Universally). Но прежде, чем показать ее в работе давайте определим то, что мы будем показывать. Я напишу вот такой код
# J=101; j=J; nx=91; ny=91; y=-9; d=0.2; #rep ny # x=-9; y2=y*y; #rep nx # r(j)=exp(-0.05*(x*x+y2)); j=j+1; x=x+d; #end # y=y+d; #end
Он вычисляет функцию Гаусса от двух переменных x и y в части массива r(), начиная с r(J) и nx*ny чисел. На самом деле функция Гаусса вычисляется операцией команды #ma намного быстрее и проще. Но я тут решил показать, как это делается на ACL. Так как точек не так много, все делается быстро. И теперь мы покажем на графике 10 кривых из этого массива на склоне, где они меняются быстрее всего. Вот как выглядит код для такой работы
# j=J+nx*31; #d 7 A j nx 10 -9 9 247 1060 #pr smau|Plain Figure\E ##smau
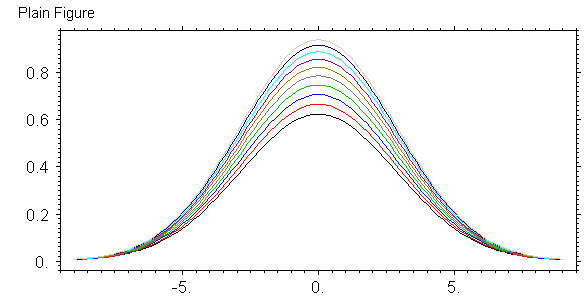 Результат показан на картинке справа от текста. Универсальная программа записывает параметры в переменные A, B, . . ., G и в два текста. Чтобы не портить переменные они в самой программе сохраняются в конце массива r(), а потом восстанавливаются. Но они портятся при задании входных данных и это минус. Это старая система, которой я пользовался какое-то время назад. Смысл параметров такой A -- начальный индекс двумерного массива, B -- число точек аргумента, C -- число кривых, D -- начальное значение аргумента, E -- конечное значение аргумента, F -- начальный номер цвета, G -- три младшие разряда показывают масштабирование в процентах, старший разряд указывает показывать график или нет. При этом 1 показывать, 0 -- нет. Также надо напечатать два текста, разделенные символом вертикальной черты. Первый текст -- это название файла для записи графика без расширения. Расширение всегда png. Второй текст -- заголовок над графиком.
Результат показан на картинке справа от текста. Универсальная программа записывает параметры в переменные A, B, . . ., G и в два текста. Чтобы не портить переменные они в самой программе сохраняются в конце массива r(), а потом восстанавливаются. Но они портятся при задании входных данных и это минус. Это старая система, которой я пользовался какое-то время назад. Смысл параметров такой A -- начальный индекс двумерного массива, B -- число точек аргумента, C -- число кривых, D -- начальное значение аргумента, E -- конечное значение аргумента, F -- начальный номер цвета, G -- три младшие разряда показывают масштабирование в процентах, старший разряд указывает показывать график или нет. При этом 1 показывать, 0 -- нет. Также надо напечатать два текста, разделенные символом вертикальной черты. Первый текст -- это название файла для записи графика без расширения. Расширение всегда png. Второй текст -- заголовок над графиком.
Разметка осей все еще выполняется автоматически, но значения вычисляются из начального и конечного значений аргумента, а также из значения функций. Нужно объяснить смысл параметра F. У ПИ есть массив цветов из 256 элементов. В каждом номере запасен определенный цвет. Эти цвета можно переопределять специальной командой #col. Исходно в программе заданы цвета в конце таблицы так, что 246 белый, 247 черный, 248 красный, 249, синий, 250 зеленый и так далее. Вот эти цвета и используются.
Другой способ изобразить двумерный массив целиком без искажения масштабов на осях аргументов реализует суперкоманда с названием ##smmx (Show Memory Map eXtanded). Она позволяет делать разметку осей в явном виде. Что касается оси функции, то в стандартном варианте она не используется, но если надо, то ее тоже можно использовать. Дело в том, что функции могут принимать разные значения от очень больших до очень маленьких и выписывать такие значения не удобно. Вместо этого массив нормируется на стандартный интервал (0, 1), а минимальное и максимальное значения функции показываются над графиком. Вот как выглядит код программы, которая показана на картинке справа
#d 15 r(1) -9 9 -5 5 4 -9 9 -5 5 4 0 1 0 0.2 2 #d 6 A J nx ny 1100 44 1 #p [pa=3;] #pr smmx|Map Figure\E ##smmx
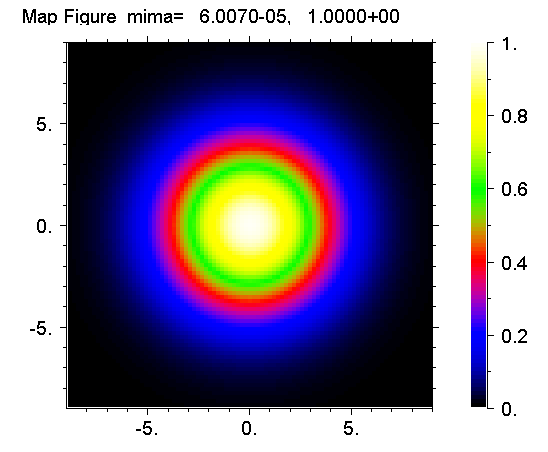 Здесь важно описать принцип разметки осей. Ось размечается с помощью пяти параметров. Это начальное и конечное значения на оси, значение первой длинной риски, шаг до следующей длинной риски и число коротких рисок между длинными. Соответственно для трех осей получаем 15 чисел. Их можно записывать куда угодно внутри массива r(). Но я обычно оставляю первые 100 значений для это цели и массивы записываю начиная от 101 элемента. Здесь эти числа записаны с самого начала. Также надо указать 6 параметров в переменных, начиная с A, указать палитру цветов в параметре [pa] и снова два текста, которые имеют тот же смысл, что и раньше. В переменных записывается начало массива, число точек по обеим осям. В переменную D надо записать то же самое, что в переменную G в предыдущей суперкоманде. В переменной E два разряда, каждый указывает число пикселей экрана на одну точку. И последняя переменная F указывает индекс массива r(), где записана разметка осей.
Здесь важно описать принцип разметки осей. Ось размечается с помощью пяти параметров. Это начальное и конечное значения на оси, значение первой длинной риски, шаг до следующей длинной риски и число коротких рисок между длинными. Соответственно для трех осей получаем 15 чисел. Их можно записывать куда угодно внутри массива r(). Но я обычно оставляю первые 100 значений для это цели и массивы записываю начиная от 101 элемента. Здесь эти числа записаны с самого начала. Также надо указать 6 параметров в переменных, начиная с A, указать палитру цветов в параметре [pa] и снова два текста, которые имеют тот же смысл, что и раньше. В переменных записывается начало массива, число точек по обеим осям. В переменную D надо записать то же самое, что в переменную G в предыдущей суперкоманде. В переменной E два разряда, каждый указывает число пикселей экрана на одну точку. И последняя переменная F указывает индекс массива r(), где записана разметка осей.
Но здесь есть дополнительные возможности. Переменные D и E могут быть отрицательными и знак указывает на другой режим работы. Так если D < 0, то показывается просто голая картинка без осей. Иногда это тоже необходимо. А если E < 0, то ось функций размечается без нормировки, по указанным значениям. Размеры текста во всех командах определяются автоматически по размерам картинки. Это необходимо, потому что картинки иногда бывают очень большим или очень маленькими и задавать размеры текста каждый раз не удобно. Параметр pa в настоящее время можно задавать как 0 для черно-белых карт и 3 для цветных. Есть еще значения 1 и 2, но они как бы устарели и не такие интересные как 3.
Эти две программы были представлены в статье ПШПВ. На самом деле таких суперкоманд больше и они являются просто модификациями указанных с некоторыми небольшими отличиями. Но есть и принципиально другие суперкоманды. Одна из них называется ##smma (Show Memory Matrix as Axonometry). Она больше годится в качестве наглядной презентации, но не годится для точного измерения размеров. Кроме того, она вообще не показывает часть массива. Я перестал использовать такие картинки в научных статьях. Но в презентациях это иногда может быть полезно. Для ее использования надо писать такой код
#d 15 r(1) -9 9 -8 4 3 -9 9 -8 4 3 0 1 0 0.2 0 #d 14 A J nx ny 1060 30 1 1 1 0.06 3 1 1 9 9 #pr #pr smma|Axonometry\E ##smma
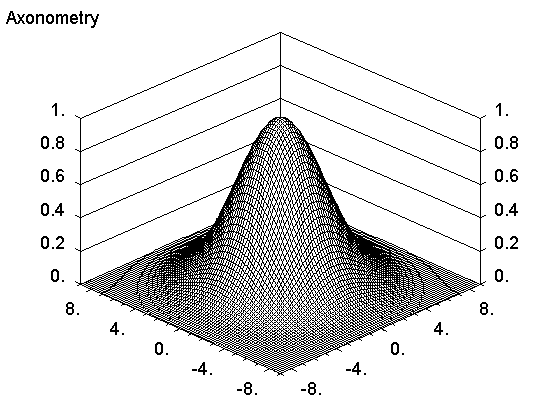 О картинках такого типа я рассказывал в статье ПШПВ в главе о простой графике. Но там использовался другой набор входных данных. Суперкоманда исправляет этот недостаток. Здесь используется точно такая же разметка осей, причем нормировка делается другим способом, сама функция не нормируется. А переменных используется больше, всего 14. Причем первые 4 и 6й имеют точно такой же смысл, остальные отличаются. Так 5й тоже состоит из двух разрядов. Старший разряд может принимать значения: 1 для x-z сечений, 2 для y-z сечений, 3 для сечений по обоим направлениям. Младший разряд может принимать значения: 0 для рисования двух вертикальных осей, 1 для рисования только правой вертикальной оси около оси X, 2 для рисования только левой вертикальной оси около оси Y. Переменные . G,H,I . задают координаты направления точки зрения, важны только отношения; . J . задает десятичный логарифм расстояния до точки зрения, . K, L . определяют масштабные коэффициенты для аргументов на осях X и Y при рисования поверхности в том случае, когда аргументы измеряются в других единицах; . M, N . определяют координаты для установки заголовка, отсчитываются от левого верхнего угла.
О картинках такого типа я рассказывал в статье ПШПВ в главе о простой графике. Но там использовался другой набор входных данных. Суперкоманда исправляет этот недостаток. Здесь используется точно такая же разметка осей, причем нормировка делается другим способом, сама функция не нормируется. А переменных используется больше, всего 14. Причем первые 4 и 6й имеют точно такой же смысл, остальные отличаются. Так 5й тоже состоит из двух разрядов. Старший разряд может принимать значения: 1 для x-z сечений, 2 для y-z сечений, 3 для сечений по обоим направлениям. Младший разряд может принимать значения: 0 для рисования двух вертикальных осей, 1 для рисования только правой вертикальной оси около оси X, 2 для рисования только левой вертикальной оси около оси Y. Переменные . G,H,I . задают координаты направления точки зрения, важны только отношения; . J . задает десятичный логарифм расстояния до точки зрения, . K, L . определяют масштабные коэффициенты для аргументов на осях X и Y при рисования поверхности в том случае, когда аргументы измеряются в других единицах; . M, N . определяют координаты для установки заголовка, отсчитываются от левого верхнего угла.
В этой программе разницу в значениях функции и аргументов можно компенсировать выбором направления точки зрения. Чем ниже z координата точки зрения, тем выше будет функция. Но алгоритм устранения невидимых линий предполагает, что все три координаты положительные. Для отрицательных координат картинка может оказаться неправильной. Если надо посмотреть что сзади, то проще инвертировать сам массив. Представленными программами арсенал способов изображения двумерных зависимостей не ограничивается. Еще в самые доисторические времена, когда графики рисовались вручную, применялась техника складывания плоских рисунков для разных функций вместе, но со сдвигом по горизонтали и вертикали, а также с устранением невидимых линий. В этом случае искажения масштабов по осям не происходило, и в то же время создавался некий эффект трехмерности.
Такие графики весьма специфичны, но иногда они тоже могут оказаться полезными. Очень давно я сделал суперкоманду, которую назвал ##smq3d (Show Memory as Quasi 3 Dimensions picture). У нее есть специфичность, которая состоит в том, что сдвиг вправо делается ровно на целое число шагов, с которым вычислены сечения. Это связано с упрощенным алгоритмом устранения невидимых линий. По этой причине хорошо выглядят только массивы, у которых число точек по оси Y вдвое меньше, чем по оси X, или еще меньше. Я покажу пример, где показаны только половина точек по оси Y. Для нашего гауссиана, который симметричен, это не такая уж большая потеря.
Кроме того, суперкоманда сразу показывает две картинки, инвертируя массив по второму аргументу. Дело в том, что одного вида спереди при таком виде рисования явно не хватает, и нужен еще вид сзади, так как невидимые линии быстро накапливаются. Ниже показан код графиков, а еще ниже результат работы этого кода.
#d 12 A J nx 46 -9 9 -9 0 20 0 20 24 0 #pr smq3d\E ##smq3d
Эта программа заголовок не ставит, соответственно необходимо напечатать только имя файла. При этом она делает два рисунка, добавляя к указанному имени буквы a и b. И необходимо определить 12 переменных, начиная с A и кончая L. Удобство использования переменных в том, что они сразу используются в коде суперкоманды. Как и раньше, первые 3 -- это начало массива и число точек по осям X и Y. Затем два числа -- это начальное и конечное значения аргумента по оси X, следующие два -- то же самое по оси Y. Переменная H определяет дополнительный сдвиг всей картинки вправо в пикселах экрана. Это может понадобиться если числа на оси очень длинные. Переменная I обычно равно нулю. В этом случае каждая следующая кривая сдвигается на один шаг по оси X. Но если число точек по оси X очень большое и шаг очень маленький, то сдвиг необходимо увеличить. Но переменная I должна быть целым числом, сдвиг делается только на целое число шагов.
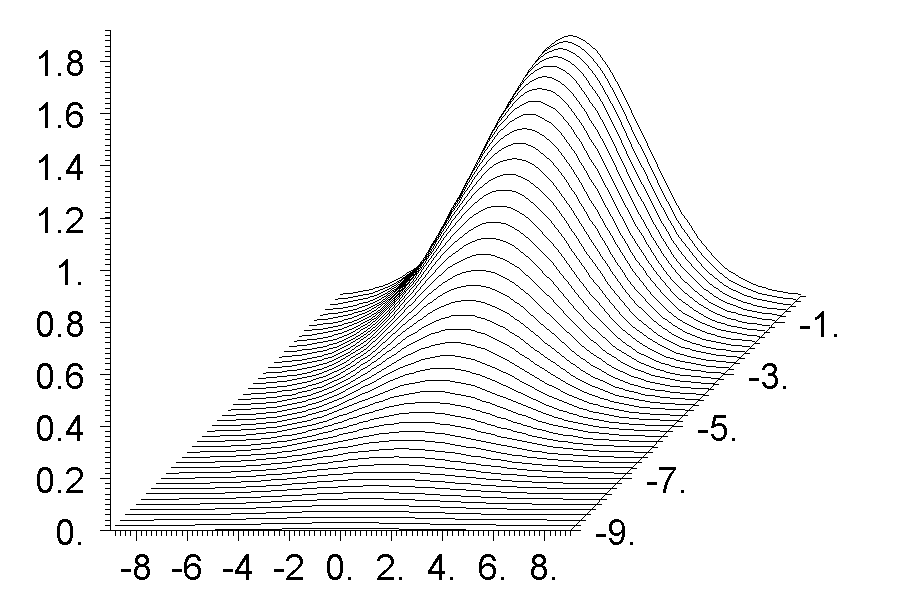
Следующее число -- это вертикальный сдвиг каждой следующей кривой в единицах 0.001 от максимального значения всего массива. Переменная K определяет размер текста в пикселах, а последнее число указывает насколько надо расширить размер графика по горизонтали, если он не влезает в стандартный размер 900 пикселей. Дело в том, что этот размер соответствует ситуации, когда число точек по вертикали в 2 раза меньше, чем по горизонтали. Но если это не так, то нужна корректировка. Как видим аргументов не так уж и много, но они весьма специфические. Разметка осей делается автоматически. Причем осей 3. Ось первого аргумента и функции нормальные, а ость второго аргумента снова квази и разметка специфическая. Вместе с тем такие графики иногда могут быть даже более предпочтительны, чем аксонометрия, потому что они ничего не искажают.
На рисунках видны особенности данного рисунка. Так как каждая следующая кривая выше предыдущей, то монотонно возрастающие кривые требуют больше места на вертикальной оси по сравнению с монотонно убывающими кривыми. Собственно такого же типа эффекты мы видим и в реальной жизни. А видимость данных графиков существенно зависит от выбора смещений каждой следующей кривой.При одной и той высоте рисунка нарастающие кривые получаются ниже, убывающие выше. Такие рисунки хорошо выглядят, когда кривых мало и они даются с крупным шагом по второму аргументу.
2. МЕТОДЫ ПРОГРАММИРОВАНИЯ. НОВЫЙ СПОСОБ РАБОТЫ С СУПЕРКОМАНДАМИ.
После того, как я написал предыдущий рассказ о программах научной графики, выполненных в виде суперкоманд, я стал снова думать о недостатках суперкоманд. Суперкоманды были придуманы в самом начале и их обработка выполнена на аппаратном уровне, то есть этим занимается интерпретатор. Но реально в этом никакой необходимости не было. Есть команда ( #e [file=proc/name.acl;] _file ) и она сразу выполняет код из файла. Вместо этого просто введено более короткое обозначение ##name. Главная идея состояла в том, чтобы не переписывать один и тот же код много раз в каждую программу. Все программы могут обратится к одному и тому же файлу и прочитать один и тот же код. В этом есть большой плюс. Часто просто нужно знать что дать такой программе на входе и что она выдает на выходе. А сам код можно даже не смотреть.
Но так можно записывать не только реальный код программы, но и определение каких-то стандартных параметров, чтобы их не переписывать каждый раз. Просто для сокращения текста. Это тоже удобно. Но есть и минусы. Очень быстро накапливается большое число файлов, в которых записано мало текста. А чтение файлов -- операция не быстрая. Кроме того, если код нужен много раз, то каждый раз надо читать файл заново. И это снова минус. То есть такие приемы хорошо годятся для научной графики, которая не часто требуется. Но какие-то расчетные модули, особенно в цикле, начнут сильно тормозить и изнашивать винчестер. Для таких программ чтение кода из файла нежелательно.
Но есть альтернатива. Код можно читать и из текстового массива t(). Тут удобство в том, что код из файла можно записать в текстовый массив один раз и потом уже его использовать многократно. Код в текстовом массиве исполняется так же быстро, как и код самой программы. Она ведь тоже записана в текстовый массив, но другой. У такого подхода есть и второй плюс. Совсем не обязательно записывать каждую суперкоманду в отдельный файл. Все равно нужна процедура для считывания кода из файла. Она может читать не весь файл, а только его часть. Я давно сделал команду, которая читает и записывает одну строку файла с конкретным номером. То есть суперкоманде достаточно присвоить номер и записать ее в строку файла с этим номером.
Интересно, что процедуру работы с файлами в таком стиле даже не обязательно писать на языке Java и включать в интерпретатор. Ее можно написать и на самом языке ACL в виде специальной процедуры. Также не обязательно выделять для таких процедур из файла отдельную память, можно выделить часть массива t(). В конце концов я придумал реализацию этой идеи, которая описана ниже. Каждая суперкоманда имеет номер из произвольного числа разрядов, например, 525. При этом все разряды выше второго образуют отдельное число -- номер файла, а два нижних разряда указывают на номер строки в файле. Так номер 525 указывает на 25-ю строку в файле (pro/proc05.txt). Исполнение такой процедуры выполняет код #e [n=525;] _scom . Фактически, это уже не суперкоманда, а процедура номер 525. Но она полностью эквивалентна суперкоманде.
Процедура ( #pro scom . . . @ ) должна быть записана в каждую программу. Она универсальна, но со временем может оптимизироваться, либо будет заменена на операцию какой-то команды. Эта процедура не просто считывает код из файла в текстовый массив. Она одновременно составляет каталог всех уже считанных процедур. А перед считыванием новой процедуры проверяет ее наличие в каталоге. Если она уже считана, то она больше не считывается, а просто используется. Это похоже на кэш в браузерах. Браузеры для ускорения своей работы тоже запоминают определенное количество сайтов в кэш, и если запрашиваемый сайт есть в кэше, то он не скачивается, а сразу показывается. Это очень мешает сайто-писателям, которые часто меняют содержание сайтов. Они не видят изменений в браузере.
Но кэш всегда можно обнулить и начать все с начала. Так и в ACL. Процедура scom использует переменные от AY до JY и UZ, VZ. Эти переменные в программах теперь использовать нельзя. Но они недавно появились и еще нигде не используются. Кроме того нужно определить начала массивов t() и i(), после которых записывается кэш до самого конца, так что концы этих массивов тоже нельзя использовать в программах. Это определяется таким образом
# AY=1990001; BY=149701; CY=0;
То есть переменная AY указывает начало кэша в массиве t(), а переменная BY указывает начало кэша в массиве i(), переменная CY указывает сколько процедур уже записано. Числа можно менять, в разных программах они могут быть разными. Обнулять кэш, если захочется можно таким способом
# C=0; n=3*CY; #ma [op=vic; b=1; le=n;] #pas n r(1) i(BY) # CY=0;
На самом деле достаточно обнулить переменную CY, но для чистоты хорошо также обнулить и целый массив. Массив t() обнулять не обязательно, он просто будет переписываться в процессе и все. В целый массив программа записывает три числа для каждой считанной процедуры -- это номер процедуры, начальный индекс массива t(), где она записана, и число знаков в записи. Как раз при запуске новой процедуры с номером данная процедура проверяет наличие ее номера в списке уже записанных номеров. Если он есть, то процедура исполняется, если нет, то считывается из файла и записывается в каталог.
Важно, что пока интерпретатор не закрыт, каталог сохраняется. Поэтому инициализацию в первой из двух записанных выше строк можно делать в самой первой программе и больше не делать. Все остальные программы могут работать с одним и тем же каталогом. Но надо понимать, что размеры кэша ограничены и пока проверка на его заполнение не делается. При записи за пределы размера массива t() программа укажет на ошибку. Но если работать с одной и той же программой много дней, то можно интерпретатор не закрывать и тогда процедуры все время будут в памяти. Тут важно отметить, что сам компьютер при этом закрывать можно. В системе Виндовс есть такой режим, который называется гибернацией.
В этом режиме система записывает всю оперативную память на винчестер и выключает компьютер. А при его включении система обнаруживает спецальный знак и просто копирует записанную оперативную память из винчестера на ее место и компьютер снова оказывается в том состоянии, в каком был до выключения. В ноутбуках с SSD винчестером это происходит очень быстро. И все программы, которые были открыты, остаются открытыми и продолжают работу так, как будто ноутбук и не выключали. К сожалению, в системе нет кнопки для такого выключения. Это делается через команду ОС с параметром. Но в интернете все написано и легко узнать, как это сделать. Нужно просто знать чего спрашивать. Поэтому для экономии времени я не стану тут об этом писать. Сам я только так и работаю. Для полноты картины я покажу код процедуры scom, а потом объясню как он работает
#pro scom #pas 2 s(4) UZ # EY=s(7); JY=int(EY/100); EY=EY-JY*10; IY=0; &=CY<1; #case 0 # UY=0; GY=1; #end |
#case 1 # DY=BY; # &=0; #case 0 # &=abs(i(DY)-EY)<1; #case 0 # UY=i(DY+1); VY=i(DY+2); FY=1; GY=0; #end |
_ #case 1 # IY=IY+1; &=(IY-CY)>0; #case 1 # UY=i(DY-2)+i(DY-1); FY=1; GY=1; #end |
_ #case 0 # DY=DY+3; FY=0; #end | #end | # &=FY; #end #end | # &=GY;
#case 1 #f [op=fold; file=pro;] # UY=UY+AY; s(3)=UY; #p [file=\u112;roc\I-2 JY;.txt\E]
_ #f [op=line; file=\u112;roc\I-2 JY;.txt\E n=-EY;] # VY=s(5); #f [op=fold; file=oldf;]
_ # DY=BY+CY*3; CY=CY+1; i(DY)=EY; UY=UY-AY; i(DY+1)=UY; i(DY+2)=VY; s(3)=UZ+VZ;
#end | #pas 2 UZ s(4) #e [b=UY+AY; le=VY;] _text @
Итак, начинаем разбираться. Некоторые суперкоманды используют текст, который печатается перед их вызовом. Параметры текста записываются в s(4), s(5). Их надо сразу запомнить в переменных UZ, VZ так как s(4) и s(5) будут переписаны в коде процедуры. Далее значение параметра [n] копируется в переменную EY и из нее выделяется номер файла в переменную JY. Затем обнуляется счетчик IY и проверяется число CY уже записанных файлов. Если 0, то все ясно, искать ничего не надо. Если больше нуля, то надо сравнить все записанные номера с указанным новым номером. Переменная DY -- это индекс целого массива, который в цикле каждый раз увеличивается на 3. Переменная GY -- это флаг на считывание из файла. Если 1 -- считываем, если 0 -- нет. Ее значение определяется. Переменная FY -- это флаг на продолжение цикла поиска. Если 0 -- цикл продолжается, если 1 -- цикл заканчивается. Второе значение получается если найдено совпадение или если счетчик IY превышает CY. При совпадении параметры записываются с переменные UY, VY и к первому прибавляется еще AY. Если совпадения нет, то из файла считывается новая процедура и ее параметры тоже записываются в целый массив. В конце восстанавливаются параметры печати и исполняется процедура.
Так как в конкретной программе процедур все-таки не так уж и много, то все это работает очень быстро. Намного быстрее, чем читать каждый раз из файла. И важно, что сам винчестер не изнашивается. Но как писать сами эти процедуры. Тут есть разные варианты. Их первоначально можно писать как обычные процедуры, или даже как обычные суперкоманды. Старый механизм работы суперкоманд остается и его можно использовать. А когда все стабильно работает, то с помощью специальной программы текст можно записать в новый файл с библиотекой суперкоманд. Перед этим я просто заменяю все символы с юникодом 10 в тексте суперкоманды на 0, и получается одна строка. А при желании можно сделать обратную замену 0 на 10. И еще все команды с продолжением, такие как # a=;, #d, #v, #e и другие в конце строки надо закрыть символом ( ! ) .
Пока я обработал такие суперкоманды:
01 (smau) | 02 (smmx) | 03 (smma) | 04 (smq3d) | 05 (paax) | 06--13 (par) | 14 (ssel) | 15 (rules) | 16 (chva) | 17 (mess) | 18 (scar) | 19 (mspic) |
20 (animdep) | 21 (matpic) | 22 (cond) | 23 (winf) | 24 (winid) |
Все они находятся в файле с номером 00. Но число суперкоманд будет все время расти. Кроме того и сейчас их очень много, но я стараюсь устаревшие версии не использовать. В суперкоманде par было 8 разных команд в одном файле, которые разделялись по значению переменной &. Сейчас в этом нет смысла и они разделены. Все описания суперкоманд остаются в силе. Просто надо знать соответствие имени и номера, как указано выше. И весь набор файлов для них также существует, просто надо стараться их реже использовать.
На самом деле для простых программ вполне можно и старые суперкоманды использовать. Места на диске хватает и число файлов -- не проблема. Проблема только в том, чтобы программе не приходилось часто читать файлы. Но в перспективе какие-то очень надежно работающие файлы суперкоманд можно будет отправлять в архив и переходить на новую систему. Я сам постепенно это делаю со своими программами. Что касается инициализации переменных AY, BY, CY, то в новой версии программы это сделано в файле (start.acl), который находится внутри файла интерпретатора и запускается первым при каждом запуске интерпретатора, так что в конкретных программах можно ничего не делать.
В описанном выше виде программа продолжает работать, но через 10 дней после того как был написан показанный выше текст, я придумал еще более крутой метод. Кроме переменных AY, BY, CY, а также заодно и ZZ, &&, я записал в файл (start.acl) и печать самой процедуры scom в массив t(), начиная с индекса KY=AY-670; И теперь совсем не обязательно записывать эту процедуру в каждую программу. Она уже в самом начале работы программы записана в текстовый массив и ее можно запускать оттуда. А код запуска выглядит так
#d 4 s(7) N & KY 670 #e text
где N должно иметь значение номера процедуры. При таком вызове процедура обязательно выполнится, потому что параметр [c] равен &. А если не надо выполнять, то & заменяем на &&.
Код запуска выглядит несколько абстрактно, но в языках программирования это допустимо. Для людей, которые не знают кода он весь выглядит как текст инопланетян. С другой стороны такой код легко находится поиском, он достаточно уникален. Но можно использовать и более привычный код вызова
#e [n=N; b=KY; le=670;] _text
И такая форма не намного длиннее. Более того, в первой форме надо потом изменить переменную & при выполнении последующих процедур, если их не надо выполнять. Вторая форма эту переменную не меняет. Это будет работать после версии (22.5.7). В более старых версиях надо поменять файл (start.acl). Но можно оставить и старый вызов процедуры #e [n=N;] _scom . И написать очень короткую процедуру
#pro scom #e [b=KY; le=670;] _text @
Это позволяет не переписывать уже написанные программы, хотя реально их еще нет, и сделать синтансис более читабельным. К сожалению интерпретатор не позволяет запоминать процедуры глобально. Они работают только в пределах конкретной программы. Только суперкоманды являются глобальными. Потому и приходится делать такие преобразования. В Java и Питоне код на самом языке является частью интерпретатора, но там используется огромное число файлов и очень сложный механизм работы с ними. Такая же ситуация в Си и других языках. Еще раз повторю, что все старые методы программирования тоже работают, так что новая система является просто альтернативно дополнительной.
Надо также не забывать, что процедура scom в своем полном виде портит параметр file, хотя некоторые суперкоманды сами по себе этот параметр не портят. Поэтому есть различия в использовании scom и суперкоманд из файла. Это тоже можно было бы исправить, но пока так, как описано выше. Поэтому после вызова этой процедуры параметр file надо определять заново. Надо также иметь в виду, что некоторые из старых программ могут использовать конец массива t() и их надо переписывать. Я намерен это делать по мере необходимости. Так что при возникновении ошибок надо про это помнить.
Сама процедура добавления новых суперкоманд в файлы-склады (pro/proc00.txt) и другие может быть такой. Сначала пишем в чистом виде суперкоманду в файл и проверяем ее работу. После того, как все проверено и ошибок нет, можно записать файл в строку файла-склада с помощью стандартной программы. Пример такой программы показан ниже
#pr smau\E # M=0; N=1; K=1;
#f [op=fold; file=null;] # s(3)=9999; #pr proc/\Tp .acl\E #f [op=size; file=\Tp\E] # nb=s(1); #io [op=rb; fir=t(999); n=nb; le=0;]
#te [op=repl; b=999; le=nb; c=13; mo=32;] # &=K; #case 1 #te [c=10; mo=0;] #end | #pr pro/proc\I-2 M;.txt\E
# a=s(4); b=s(5); #f [op=line; file=\Ta b\E n=N; em=0;] #e [n=6; b=KY; le=670;] _text #f [file=\Ta b\E]
Здесь в первой строке нужно указать название суперкоманды, а в переменных M, N, K -- номер файла-склада, номер суперкоманды, 1 если все записывается в одну строку и 0, если нет. Значение K=0 отменяет замену символа 10 на 0. Это входные данные. Сам текст процедуры стандартный. Для удобства я записал этот текст, как первый вариант файла (pro/data/service.pro). Его можно открыть по кнопке (Player), отредактровать и испольнить. В этот файл я буду записывать разные служебные программы. Данная программа -- первая.
.